Programmer's Guide
Documentation for programmers.
Process Loop
The MOOSE main process loop coordinates script commands, multiple threads to execute those commands and carry out calculations, and data transfer between nodes.
Threads
MOOSE runs in multithread mode by default. MOOSE uses pthreads.
1. The main thread (or the calling thread from a parser such as Python) is always allocated.
2. MOOSE estimates the number of CPU cores and sets up that same number of compute threads. To override this number, the user can specify at the command line how many threads to use for computation.
If MOOSE is running with MPI, one more thread is allocated for controlling MPI data transfers.
MOOSE can also run in single-threaded mode. Here everything remains in the 'main' thread or the parser thread, and no other threads are spawned.
Multithreading and the Process Loop
The MOOSE process loop coordinates input from the main thread, such as parser commands, with computation and message passing. MOOSE has one process loop function (processEventLoop) which it calls on all compute threads. All these threads synchronize on custom-written barriers, during which a special single- thread function is executed.
The sequence of operations for a single-node, multithread calculation is as follows:
1. The Process calls of all the executed objects are called. This typically triggers all scheduled calculations, which emit various messages. As this is being done on multiple threads, all messages are dumped into individual temporary queues, one for each thread.
2. The first barrier is hit. Here the swapQ function consolidates all the temporary queues into a single one.
3. All the individual threads now work on the consolidated queue to digest messages directed to the objects under that thread. Possibly further messages will be emitted. As before these go into thread-specific queues.
4. The second barrier is hit. Now the scheduler advances the clock by one tick.
5. The loop cycles back.
In addition to all this, the parser thread can dump calls into its special queue at any time. However, the parser queue operates a mutex to protect it during the first barrier. During the first barrier, the queue entries from the parser thread are also incorporated into the consolidated queue, and the parser queue is flushed.
These steps are illustrated below:
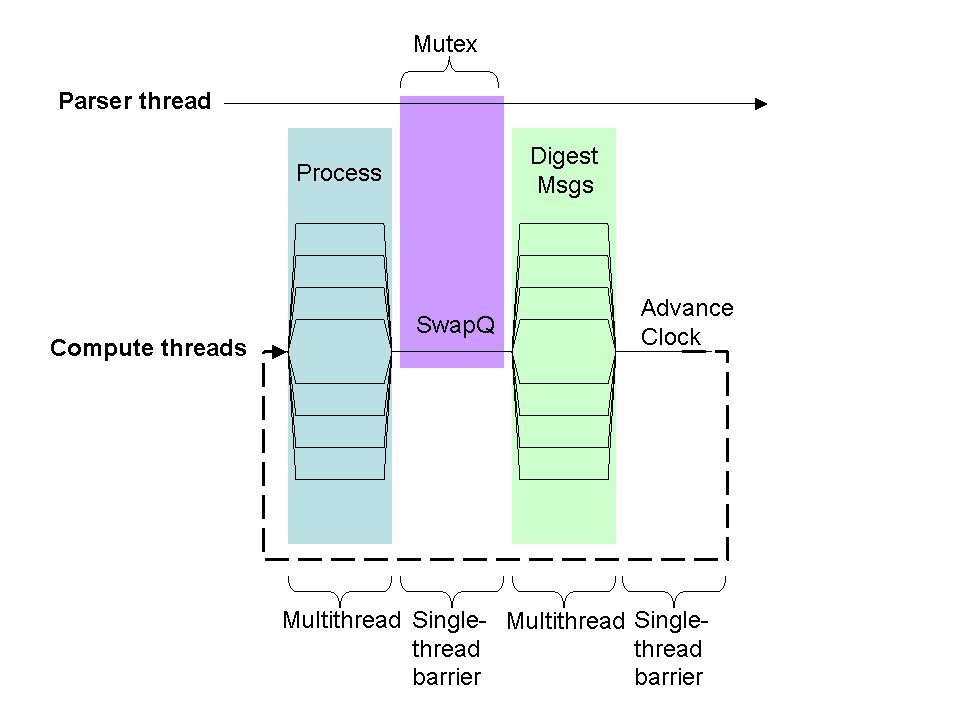
MOOSE threading and Process Loop
Multinode data transfer, Multithreading and the Process Loop
MOOSE uses MPI to transfer data between nodes. The message queues are already in a format that can be transferred between nodes, so the main issue here is to coordinate the threads, the MPI, and the computation in a manner that is as efficient as possible. When carrying out MPI data transfers, things are somewhat more involved. Here we have to additionally coordinate data transfers between many nodes. This is done using an MPI loop (mpiEventLoop) which is called on a single additional thread. MPI needs two buffers: one for sending and one for receiving data. So as to keep the communications going on in the background, the system interleaves data transfers from each node with computation. The sequence of operations starts out similar to above:
1. The Process calls of all the executed objects are called. This typically triggers all scheduled calculations, which emit various messages. As this is being done on multiple threads, all messages are dumped into individual temporary queues, one for each thread. MPI thread is idle.
2. The first barrier is hit. Here the swapQ function consolidates all the temporary queues into a single one.
3. Here, rather than digest the local consolidated queue, the system initiates an internode data transfer. It takes the node0 consolidated queue, and sends it to all other nodes using MPI_Bcast. On node 0, the command reads the provided buffer. On all other nodes, the command dumps the just-received data from node 0 to the provided buffer. The compute threads are idle during this phase.
4. Barrier 2 is hit. Here the system swaps buffer pointers so that the just-received data is ready to be digested, and the other buffer is ready to receive the next chunk of data.
5. Here the compute threads digest the data from node 0, while the MPI thread sends out data from node 1 to all other nodes.
6. Barrier 2 comes round again, buffer pointers swap.
7. Compute threads digest data from node 1, while MPI thread sends out data from node 2 to all other nodes.
... This cycle of swap/(digest+send) is repeated for all nodes.
8. Compute threads digest data from the last node. MPI thread is idle.
9. In the final barrier, the clock tick is advanced.
10. The loop cycles back.
As before, the parser thread can dump data into its own queue, and this is synchronized during the first barrier.
These steps are illustrated below:
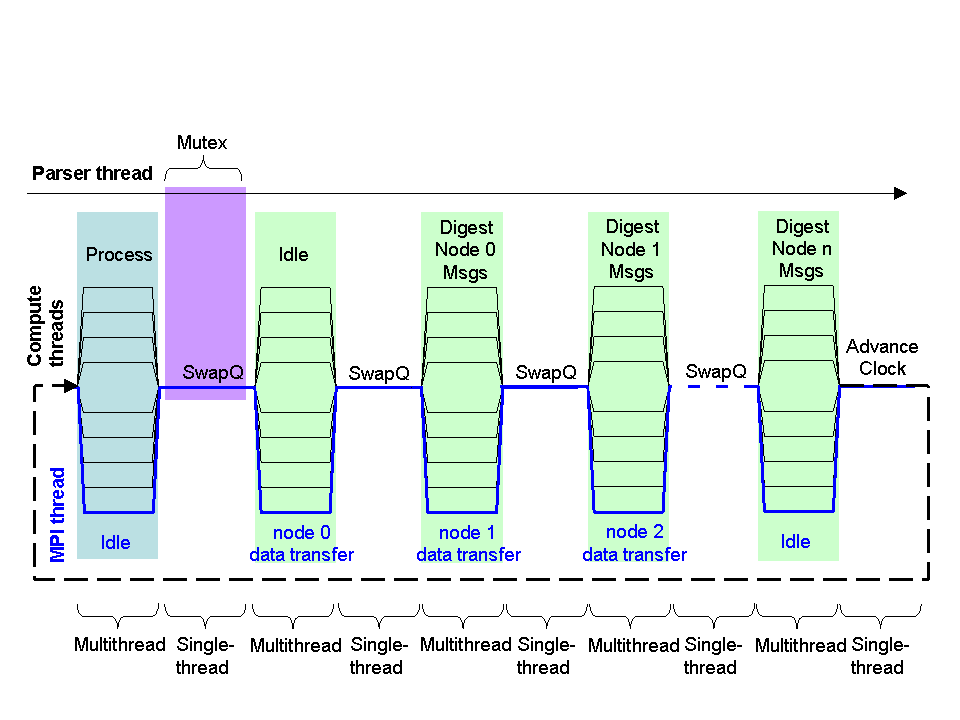
MOOSE threading and Process Loop with MPI data transfers between nodes.
Threading with the Kinetics GSL solver.
Currently we only subdivide voxels, not parts of a single large model within one voxel.
- The GslIntegrator handles Process and Reinit. This drives the data structures set up by the Stoich class.
- The Compartment, which is a ChemMesh subclass, is subdivided into a number of MeshEntries (voxels).
- The GslIntegrator has to be created with as many instances as there are MeshEntries (voxels) in the mesh.
- The setup function (currently manual) calls the GslIntegrator::stoich() function on all instances of GslIntegrator (e.g., using setRepeat).
-
The scheduling (currently manual) does:
- Clock0: MeshEntry::process.
- Clock1: GslIntegrator::process.
- During Reinit, the GslIntegrator builds up a small data structure called StoichThread. This contains a pointer to the Stoich, to the ProcInfo, and the meshIndex. There is a separate StoichThread on each GslIntegrator instance.
-
During Process on the MeshEntry, the following sequence of calls ensues:
- ChemMesh::updateDiffusion( meshIndex )
- Stoich::updateDiffusion( meshIndex, stencil )
- Iterate through stencils, calling Stencil::addFlux for meshIndex
- In Stencil::addFlux: Add flux values to the Stoich::flux vector.
-
During Process on the GslIntegrator:
- the GslIntegrators on all threads call their inner loop for advancing to the next timestep through gsl_odeiv_evolve_apply.
- The GslIntegrators on all threads call Stoich::clearFlux.
-
During Process on the Stoich, which is called through the GslIntegrator functions, not directly from Process:
-
Through the GSL, Stoich::gslFunc is called on each thread. This calls the innerGslFunc with the appropriate meshIndex. This does the calculations for the specified voxel. These calculations include the chemistry, and also add on the appropriate flux terms for each molecule at this meshIndex.
-
The Stoich::clearFlux function zeroes out all the entries in the flux_ vector at the specified meshIndex.
-
Through the GSL, Stoich::gslFunc is called on each thread. This calls the innerGslFunc with the appropriate meshIndex. This does the calculations for the specified voxel. These calculations include the chemistry, and also add on the appropriate flux terms for each molecule at this meshIndex.
Solvers and Zombies
Overview
Writing Zombies
Zombies are superficially identical classes to regular MOOSE classes, only they are now controlled by some kind of numerically optimized solver. The role of the Zombie is to give the illusion that the original object is there and behaving normally (except perhaps computing much faster). All the original messages and fields are preserved. It is important that there be a one-to-one match between the original and zombie list of Finfos in the Cinfo static intialization.
Zombies provide an interface between the original fields and the solver. They usually do so by maintaining a pointer to the solver, and using its access functions.
Zombie classes typically also provide two special functions:
zombify( Element* solver, Element* orig) and unzombify( Element* zombie). These do what you might expect from the name. The solver calls these operations during setup.
There are two main kinds of zombies:
- Soulless zombies: These lack any data whatsoever, and are derived classes from the solver. The Zombie data is nothing but a pointer to the managing solver, and is never duplicated. These are managed by a ZombieHandler. During the zombify routine, all the relevant data goes over to the solver, and the original data and dataHandler is deleted.
- Transformed Zombies: These carry some data of their own, as well as a pointer to the managing solver. If they are converted to an array, or resized they have to have their own data resized too. These are managed by a regular DataHandler. During the zombify routine, some parts of the data are copied over to the new Zombie data structure, some go to the solver, and the rest is discarded. The original data is deleted.
Writing new MOOSE classes
Overview
MOOSE is designed to make it easy to set up new simulation classes. This process is discussed in detail in this section. Briefly, the developer provides their favourite implementation of some simulation concept as a class. The functions and fields of this class are exposed to the MOOSE system through a stereotyped ClassInfo structure. With this, all of the MOOSE functionality becomes available to the new class.
Functions on MOOSE objects
MOOSE provides a general way for objects to call each other's functions through messaging, and for the script to also call these functions. To do this functions are exposed to the API in two layers. The top layer associates names with each function, using Finfos. A DestFinfo is the most straightforward way to do this, as it handles just a single function. ValueFinfos and their kin are associated with two functions: a set function and a get function.
The second layer wraps each function in a consistent form so that the message queuing system can access it. This is done by the OpFunc and its derived classes, EpFunc, UpFunc, GetOpFunc, ProcOpFunc, and FieldOpFunc. The form of the wrapping in all cases is:
void op( const Eref& e, const Qinfo* q, const double* buf ) const
The job of each of these classes is to then map the arguments in the buffer to the arguments used by the object function. Here are some of the key features:
-
OpFunc: These contain just the arguments to the function. For example:
OpFunc1< Foo, double >( &Foo::sum ); ... void Foo::sum( double v ) { tot_ += v; }These are useful when the function only operates on the internal fields of the destination object.
-
EpFunc: These pass the Eref and the Qinfo in ahead of the other function arguments. This is essential when you want to know about the MOOSE context of the function. For example, if you need to send a message out you need to know the originating object and thread. If you want to manipulate a field on the Element (as opposed to the individual object), again you need a pointer to the Eref. If your function needs to know what the originating Object was, it can get this from the Qinfo. For example:
EpFunc1< Bar, double >( &Bar::sum ); ... void Bar::sum( const Eref& e, const Qinfo* q, double v ) { tot_ += v; Id src = q->src(); msg->send( e, q->threadNum(), tot_, src ); } -
UpFunc: These are used in FieldElements, where the actual data and operations have to be carried out one level up, on the parent. For example, Synapses may be FieldElements sitting as array entries on a Receptor object. Any functions coming to the Synapse have to be referred to the parent Receptor, with an index to identify which entry was called. UpFuncs do this.
static DestFinfo addSpike( "addSpike", "Handles arriving spike messages. Argument is timestamp", new UpFunc1< Receptor, double >( &Receptor::addSpike ) ); // Note that the DestFinfo on the Synapse refers to a function // defined on the Receptor. ... void Receptor::addSpike( unsigned int index, double time ) { Synapse& s = synTable[index]; s.addEvent( time ); } - ProcOpFunc:
- GetOpFunc:
- FieldOpFunc:
